Model Training
You can configure and retrain your trained models in the Models screen after entering your project.
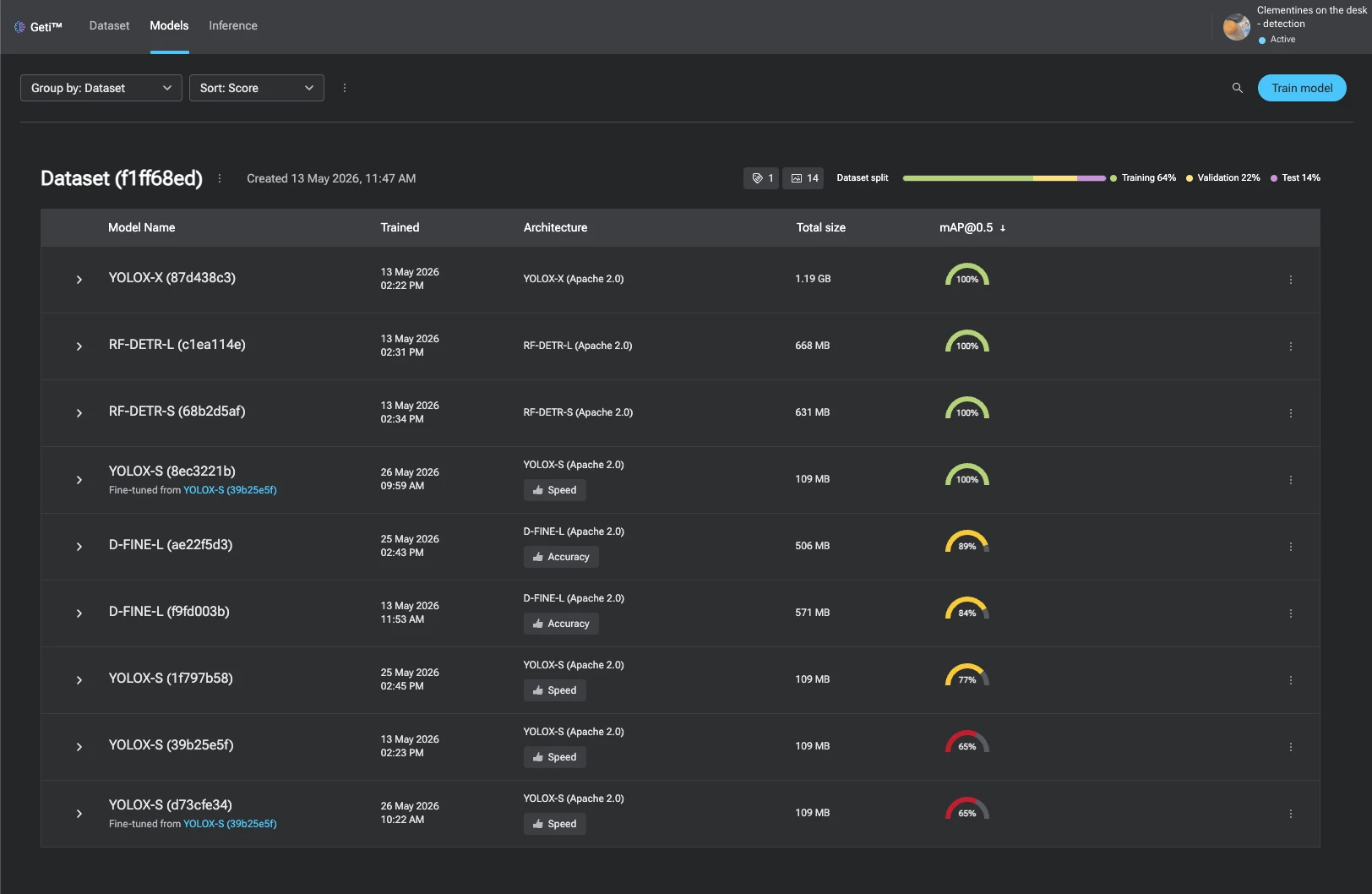
Here, you can perform transfer learning (training a new model from the base model) by pressing Train model. It invokes a dialog with the settings to configure for training.

Note
Transfer learning it's a machine learning technique where a model developed for a particular task is reused as the starting point for a model on a second task. This is beneficial because it leverages pre-existing knowledge, reducing the amount of data and computational resources required to train a new model. In Geti™, transfer learning allows you to train new models from a base model, accelerating the training process and potentially improving model performance.