Intel® Geti™ 2.0.0#
Release Highlights#
Intel® Geti™ 2.0.0 introduces significant improvements and new capabilities. These are the key highlights of the release:
Live Data Capture and Inferencing Support - Pull current data from external cameras into the platform for data labeling, model training, or live inference testing.
Advanced Annotation Mapping into Different Task Types - Automatically convert data annotation to other training tasks for easy dataset adaptation and project experimentation.
Achieve More Effective AI Models Faster with Vision Transformer (ViT) and New Model Architectures - Boost accuracy and efficiency in training tasks.
Supercharge Model Training with Intel GPUs - Broadening hardware compatibility with Intel Max 1100 support.
Flexible GPU Compatibility Checks - Leverage a broader range of GPUs that meet the necessary memory specifications for model training.
Other Intel Geti 2.0.0 updates include:
Automatic IP Address Handling - Ease server migration with automatic IP configuration changes.
New Adjustable Parameter for Better Segmentation Predictions on Small Objects - Configure the Intersection over Union (IoU) threshold number to improve segmentation model predictions and performance.
Streamline Data Import and Export Functionalities for Large Datasets - Improved system performance and memory utilization on dataset import and export operations.
Support for OpenVINO 2023.3 - Tap into the OpenVINO 2023.3 functionality.
Improved Labeling Efficiency with a Stylus - Automatically select and remove objects with a stylus.
Responsive Sliders in Annotator Screen - Real-time responsive sliders for faster and more efficient filtering and navigation.
New Model Lifecycle Management System - A method for managing the evolution of models within the platform, from introduction to deprecation and obsolescence.
Improved Dataset and Project Import and Export - Run multiple import and export jobs simultaneously.
Expanded Job Scheduler Functionality - Manage jobs with ease through filters, detailed tracking, and policies.
Scalable Inference Mechanisms - Reach inference results faster, even with multiple projects.
Smaller Storage Footprint - Saliency map data is now reduced while preserving the same level of detail.
Additional Data Format Support - Leverage JFIF for image and WebM format for video data.
SDK Support for Cloud Instances - Simplify and automate development pipelines with the SDK support for REST API, which is now available not only for on-prem deployments but also for cloud-based trial instances.
REST API Updates from 1.8.0 to 2.0.0 - See what is new.
Note
Upgrade Path Instructions - A two-step upgrade process is needed for customers currently on Intel Geti 1.5.0 or earlier versions. Users must first upgrade to any Intel Geti 1.8.* version, then upgrade to 2.0.0.
Warning
Important - Upgrading from Intel Geti 1.8.* to 2.0.0 may take several hours. Please do not interrupt this process. Make sure to give it enough time to finish.
Release Details#
This section covers additional details on the new functionality available with Intel® Geti™ 2.0.0.
Live Data Capture and Inferencing Support#
The platform now offers a comprehensive live data capture feature for real-time data interactions. This update introduces a ‘Live View’ option for performing live inferences via connected cameras, accessible within the Tests menu. Users can effortlessly select the external camera source, and the system supports on-demand capture of single frames, which are automatically added to the dataset.
In addition, this feature allows for label pre-selection for incoming data, simplifying subsequent annotations. The interface also displays the count of captured data. Users also have the flexibility to designate the capture location, either to the default dataset or a specific test dataset. With full mobile responsiveness, this live data capture functionality is accessible and efficient across all devices, providing a seamless experience in data collection and quick testing.
Advanced Mapping Capabilities for Imported Annotations#
Now, users can convert imported annotations to different task types. This feature is vital to adapt existing datasets by switching or experimenting between training tasks (i.e. from anomaly classification to single label classification)
To maintain the integrity and compatibility of datasets, these are the supported task conversions and limitations depending on the source:
For public format datasets (e.g., VOC, COCO) and non- Intel Geti exported Dataset Management Framework (Datumaro):
Labels can only be converted to classifications.
Bounding boxes (bbox) are restricted to normal detection.
Polygons are limited to instance or semantic segmentation.
This approach is to minimize compatibility issues, as we have limited control over these external formats.
For Intel® Geti™-exported Datumaro formats, more flexible cross-type projects are enabled:
Instance and semantic segmentation can be converted to normal detection. However, conversion to rotated detection is not supported, as the use case is not prevalent.
Anomaly classification can be mapped to classification.
Anomaly detection can be mapped to classification or anomaly classification.
Anomaly segmentation can be adapted to classification, anomaly classification, or anomaly detection.
Achieve More Effective AI Models Faster with Vision Transformer (ViT) and New Model Architectures#
The new models come fully equipped with compatibility for OpenVINO FP16, FP32 and INT8 IR formats, optimized through advanced techniques such as Post-training Optimization Tool (POT) or Neural Network Compression Framework (NNCF). This ensures that the models are primed for efficient deployment across various hardware platforms.
Here is a list of the expanded model suite:
DeiT-Tiny
YOLOX-TINY
YOLOX-X
YOLOX-S
YOLOX-L
Resnext101_atss
MaskRCNN-SwinT-FP16
SegNext-t
SegNext-s
SegNext-b
Supercharge Model training with Intel® GPUs#
Intel Geti platform now supports Intel Max 1100 for on-prem classification, detection, and anomaly model training tasks. The platform automatically detects the connected GPU, adjusting available options based on compatibility.
Tooltips and info pop-ups highlight any constraints and provide updates on upcoming support for additional model training tasks.
Flexible GPU Compatibility Checks#
The new release improves GPU card checks, ensuring better compatibility and performance optimization for diverse hardware setups.
Previously, the installer’s GPU compatibility checks required a validated GPU for model training. Under the new system, the installer will assess the available memory of the connected GPU against the minimum memory requirement as outlined in our Installation Guide. This change allows users the flexibility to utilize a wider range of GPUs that meet the necessary memory specifications but might not be formally validated.
If a GPU does not meet these minimum memory requirements, the installer will display a descriptive warning, clearly communicating the deficiency to the user. Installation will not proceed unless the GPU’s memory meets or exceeds the required threshold.
Automatic IP Address Handling#
Previously, when moving a server with the Intel Geti platform installed to a different network, users manually ran a script to update the platform IP address to access the platform through a browser.
This update removes the need to manually run the IP address script. Now, when the Intel Geti server’s IP address changes, users can access the platform directly by entering the new server IP address in the browser.
New Adjustable Parameter for Better Segmentation Predictions on Small Objects#
Use cases requiring detailed segmentation of multiple small objects might require manual parameter adjustment to the IoU threshold. The IoU threshold is a common metric that specifies the amount of overlap between the predicted and actual object annotations on a dataset. Tweaks to the IoU value can prevent overlapping predictions, easing data annotation, and improving overall model performance. To address this, a configurable IoU threshold parameter has been introduced:
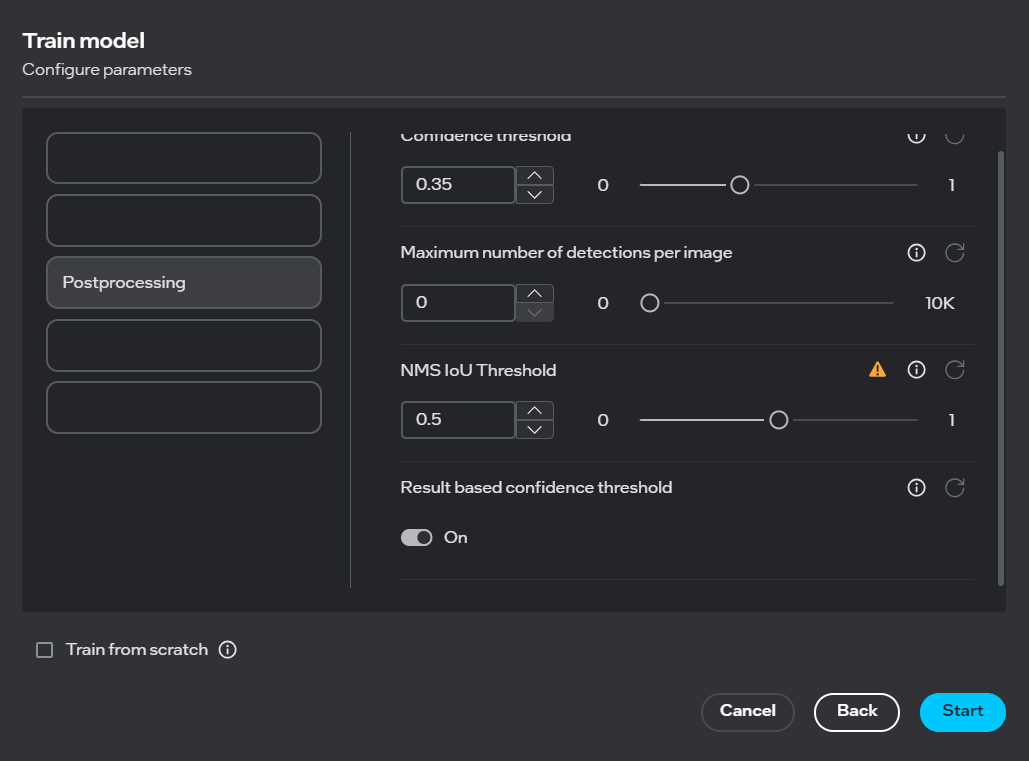
The default threshold is set to 0.5, and adjustable between values of 0 and 1.
Streamline Data Import and Export Functionalities for Large Datasets#
There is a significant overhead users experience when handling large-scale datasets such as MS-COCO, which can include over 100,000 data points in a single JSON file, necessitating around 3GB of memory just for parsing. To ease these complexities, the data importer and exporter functionalities within Datumaro were redesigned to significantly reduce memory consumption while managing large datasets efficiently.
The scope of these improvements includes support for both the Datumaro and MS-COCO formats, ensuring users utilizing these popular dataset standards will see a marked improvement in performance and reduced memory usage.
Support for OpenVINO 2023.3#
The Intel Geti platform supports OpenVINO 2023.3. You can export optimized models for deployment with OpenVINO 2023.0 to run on the latest Intel hardware.
Learn more about OpenVINO 2023.0 here.
Improved Labeling Efficiency with a Stylus#
Label data with a stylus by automatically choosing actions through the stylus tip and eraser to select and remove objects for interactive segmentation and object detection tasks.
Responsive Sliders in Annotator Screen#
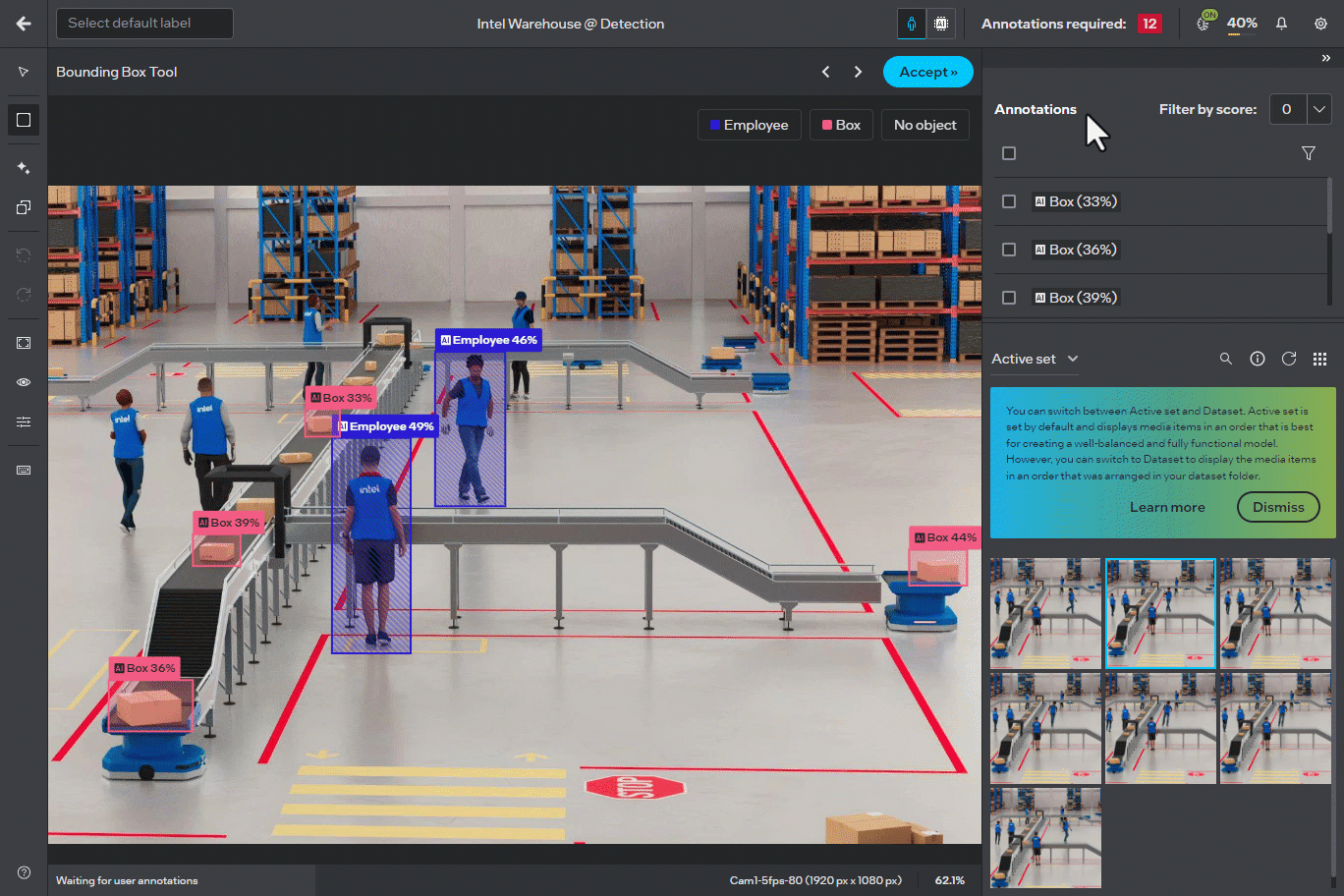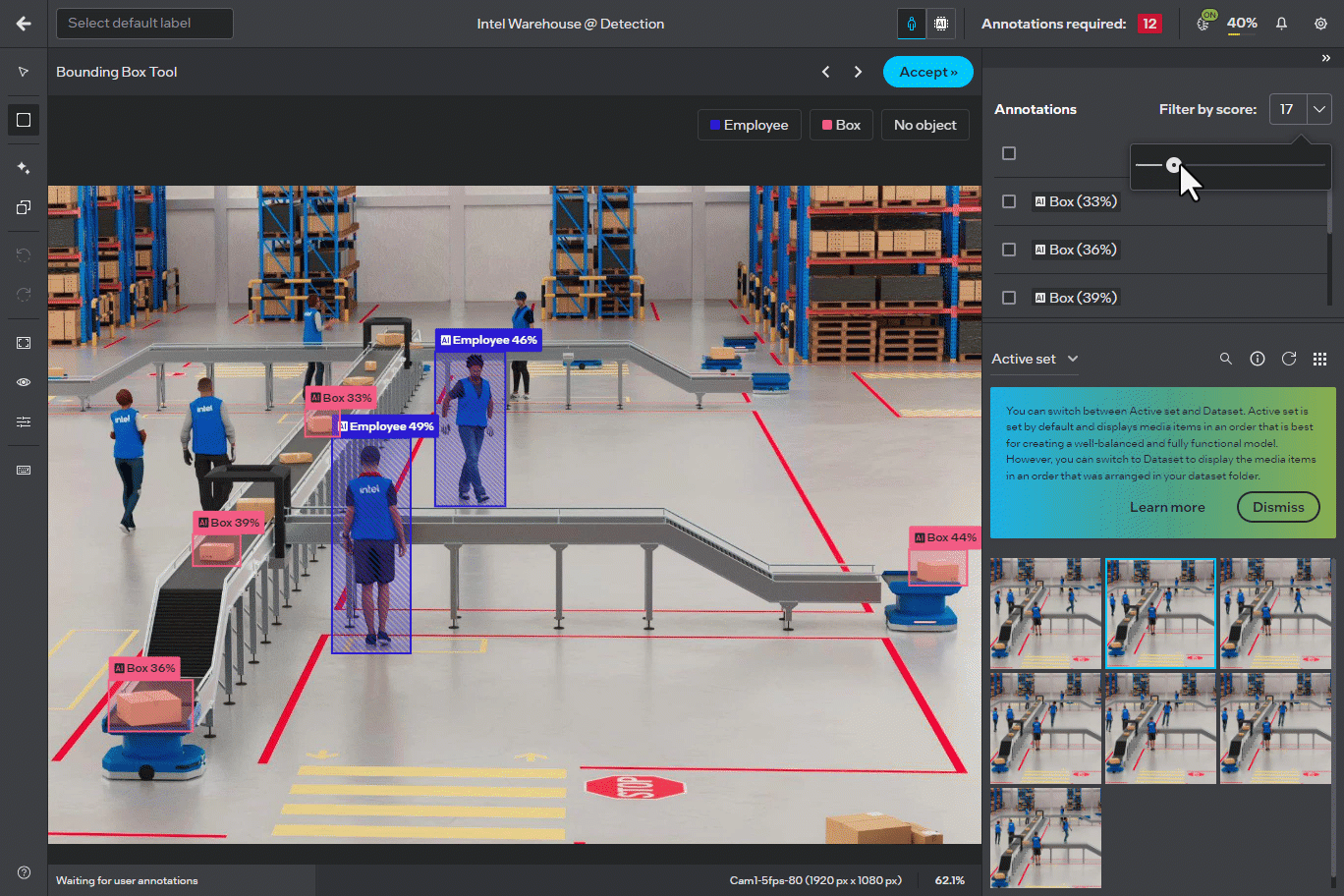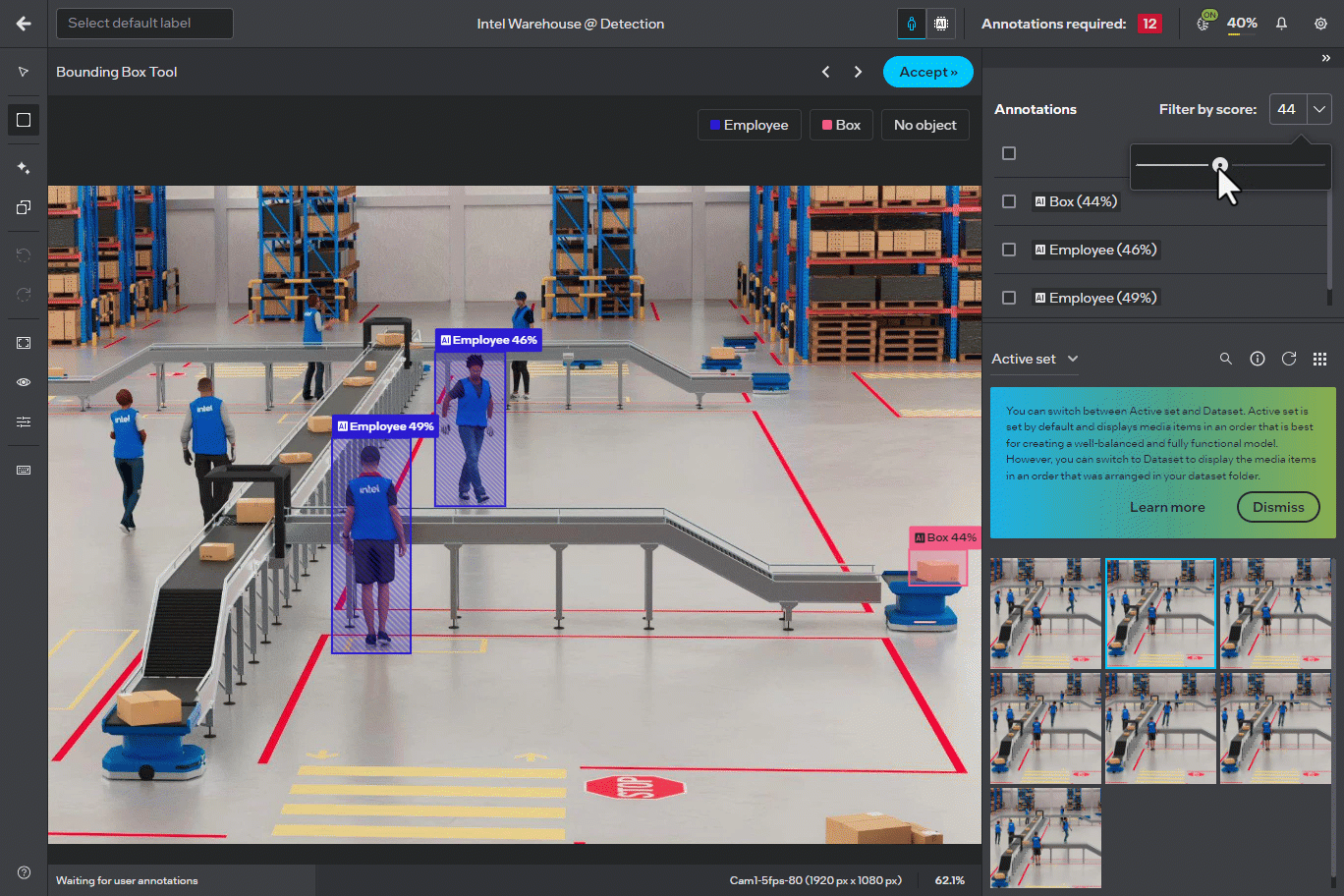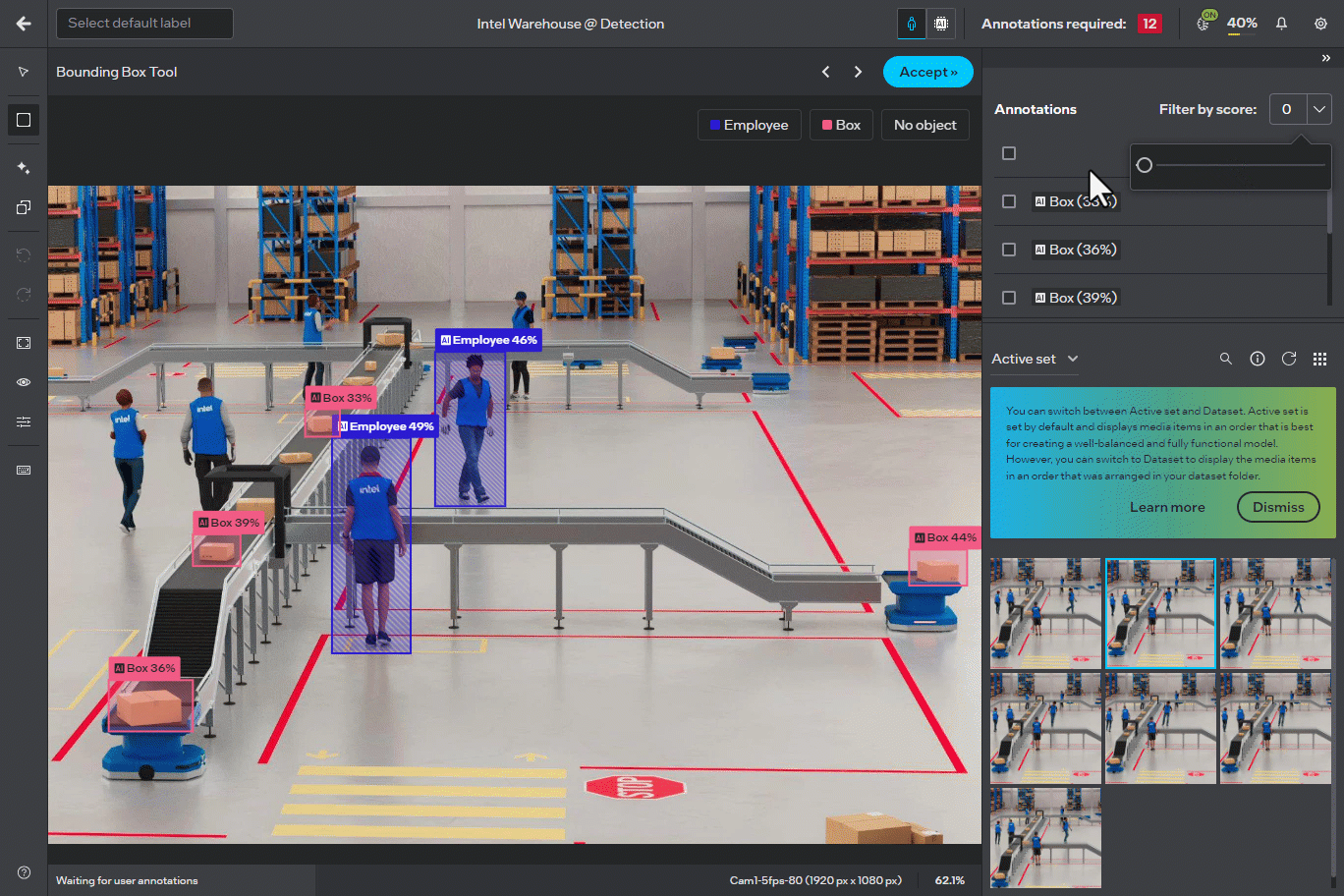
The UI sliders across different tools in the annotator screen, such as the “Filter by score” and “Detection assistant”, are now updated for real-time filtering without needing to release the slider. This change provides a more consistent and fluid experience in adjusting parameters in real-time.
New Model Lifecycle Management System#
All models are now categorized into three key stages: Active, Deprecated, and Obsolete.
Active Models: These models, designated as Recommended, receive full support. The system automatically selects the default model based on optimal performance across the initial 12 annotated images or frames.
Deprecated Models: Tagged for eventual removal, these models are still available for training. They appear exclusively under the All model template tab and are not advised for new training projects. Deprecated models include details about their phase-out status, support termination timeline, and suggestions for alternative models. When existing models enter this stage, users receive prompts to transition to newer models.
Obsolete Models: Models in this stage either become invisible or unselectable in the model templates list. If obsolete models were used, the user will receive notifications on the Model screen, along with guidance to train with new models.
See Model lifecycle to learn more.
Improved Dataset and Project Import and Export#
Dataset and project import and export processes are now defined as jobs. This means that multiple datasets and project imports and exports can run simultaneously.
Also, project import will automatically support the platform upgrade process starting from this release. For example, projects exported on Intel Geti version 2.0.0 will be importable to future platform versions.
Expanded Job Scheduler Functionality#
The platform job scheduler for data export and import, model training, optimization, and model testing offers this new functionality:
The job scheduler is now scalable and can be used for all long-running tasks, including dataset and project import/export
The job history will be available even after restarting the platform, as jobs are now persistent
Additional job filtering and sorting capabilities are now available
Jobs are described in more detail with different steps, which individually contain progress, warning, and error messages.
A new policy was implemented to configure the number of same-type jobs running concurrently. For GPU-dependent jobs, the configuration can be dynamically tied to the number of GPUs available in the system.
Scalable Inference Mechanisms#
Now, the active models for all projects are loaded simultaneously. This means no more limitation of 3 inference servers and extended loading time for inference results.
Smaller Storage Footprint#
Large, generated data in the platform, such as saliency maps, have been significantly reduced in size, while providing the same visualization details. Also, these saliency maps will be deleted after a certain period to preserve storage but could be easily regenerated when users request them.
New Data Formats#
Leverage image date in JFIF format and WebM for video date in the Intel Geti platform.
SDK Support for Cloud Instances#
The Intel Geti platform SDK’s support for Representational State Transfer (REST) API simplifies and automates development pipelines. This includes capabilities such as project creation, data and model download, and deployment, making it an invaluable tool for developers seeking to optimize and enhance their workflows.
Key to this release is the compatibility of the Intel Geti™ Python SDK, available through ‘pip,’ with both Intel Geti cloud-based trial instances plus on-premise or private instances. With this unified approach, the SDK ensures a seamless and consistent experience, bridging the cloud-based trial and on-premises deployment experience with the Intel® Geti platform.
You can access the Intel® Geti™ SDK directly through the PyPi repository at Intel® Geti™ repository in PyPi. Additionally, the SDK source code is available on GitHub, which you can visit at Intel® Geti™ SDK on GitHub.
Intel® Geti™ REST API Updates from 1.8.0 to 2.0.0#
All endpoints#
Organizations#
Support for different organizations has been added, now every endpoint starts with an organization ID:
base_url = <ip_address>/api/v1/organizations/<organization_id>/workspaces/<workspace_id>
Projects endpoints#
Projects endpoint can now filter on name using a query parameter.
The project sizes can be returned with the query parameter
with_size=true.The project performance now includes a list of
task_performances, each containing thetask_idandscorefor each task, as well as the local and global score whenever applicable.The field
task_node_idhas been renamed totask_id.The supported algorithms endpoint has been moved from
GET <ip_address>/api/v1/supported_algorithms
to within the projects domain:
GET {base_url}/projects/{project_id}/supported_algorithms
Now the endpoint returns only the supported algorithms for the tasks present in the project. It no longer accepts a task_id as query parameter. Moreover, it returns the performance_category (balance, speed, accuracy, other) and lifecycle_stage (active, deprecated, obsolete).
- The field algorithm_name is now just called name, a default_algorithm Boolean indicates if it is the default algorithm for Geti andthe now obsolete default_algorithms list has been removed.
Dataset endpoints#
When creating a new (testing) dataset,
use_for_trainingcan no longer be set. Use the default training dataset instead (the dataset created together with the project).The dataset statistics no longer contain a
performancefield.
Media endpoints#
Annotation scene state per task is now nullable. Videos will not have an annotation scene state.
Removed GET endpoints to list media, video and images#
Removed the following endpoints that respectively list all media, all images and all videos:
GET {base_url}/projects/<project_id>/dataset/<dataset_id>/media
GET {base_url}/projects/<project_id>/dataset/<dataset_id>/media/images
GET {base_url}/projects/<project_id>/dataset/<dataset_id>/media/videos
As alternative use the following endpoint:
POST {base_url}/projects/<project_id>/dataset/<dataset_id>/media:query
with empty payload {} to list all media, and with the following payloads to list all images and all videos:
{"condition":"and","rules":[{"field":"MEDIA_TYPE","operator":"EQUAL","value":"image"}]}
{"condition":"and","rules":[{"field":"MEDIA_TYPE","operator":"EQUAL","value":"videos"}]}
Filtering endpoints#
All dataset filter endpoint no longer supports
containsas operator. Useregexinstead.In the response of any filter endpoint, the field
state(string) is replaced withannotation_state_per_taskcontaining an array of all tasks and the annotation scene state for that task for that media.For the video frame filtering endpoint,
POST {base_url}/project_id}/datasets/{dataset_id}/media/videos/{video_id}:query
we now have an extra query parameter include_frame_details.
When set to false, the endpoint will only return the frame indices, no longer video frame details.
Moreover, the response now has two additional fields:
video_information, containing general video info like height, width, etc.video_frame_indices, containing a list of video frame indices that satisfy the filter.
Annotation endpoints#
The label name and label colour has been removed from the annotation response.
Prediction endpoints#
Intel® Geti™ 2.0.0 comes with a new implementation of the inference server and the old prediction endpoints are either removed or deprecated.
Both the request and response of the prediction endpoints have changed as well.
New pipeline prediction endpoints for single images or video frames:
POST {base_url}/projects/{project_id}/pipelines/{pipeline_id}:predict
POST {base_url}/projects/{project_id}/pipelines/{pipeline_id}:explain
The <pipeline_id> can be ‘active’ to obtain a prediction for the latest active model(s), or a task id, to obtain a prediction for the latest active model for only one task in a task chain. The payload is either an image file directly, or an image or video frame identifier:
{ dataset_id: <dataset_id>, image_id: <image_id> }
{ dataset_id: <dataset_id>, video_id: <video_id>, frame_index: <integer> }
The endpoint accepts two query parameters:
roito indicate the detection box for which we want a prediction.use_cache=true/falseto either reuse already made predicitons or force a new fresh prediction from the model.
For a range of video frames, the following pipelines exist:
POST {base_url}/projects/{project_id}/pipelines/{pipeline_id}:batch_predict
POST {base_url}/projects/{project_id}/pipelines/{pipeline_id}:batch_explain
The payload is a video range identifier:
{ dataset_id: <dataset_id>, video_id: <video_id>, start_frame: <integer>, end_frame: <integer>, frame_skip: <integer> }
Other than that it accepts the same path and query parameters.
Test endpoints#
For a model test response, the
model_infonow also contains thetask_id.
Train endpoints#
A training request can no longer contain
enable_pot_optimization. Instead first train a model, then optimize the model using the already existing optimze endpoint.The train endpoint no longer accepts a list of training_parameters. Instead a single training_parameter object is now the root of the payload.
The train endpoint no longer returns a list of job ids, instead returns only one job id.
Jobs endpoints#
The jobs endpoints has many new query parameters to filter the jobs returned:
project_id
job_state
job_type
key
author_id
start_time_from
start_time_to
skip
limit
jobs_sort_by
sort_direction
All job trigger endpoints now only allow one job to be started in a single request (train/optimize/tests/project import&export/dataset import&export).
Job trigger endpoints now return a single job_id instead of a list.
The response no longer holds a description field and status object. The job status can now be derived from the contents of the steps array.
Jobs also no longer calculate the time_remaining for a job, this field has been removed from the project status response.
Jobs can be cancelled through a new cancel endpoint:
POST {base_url}/jobs/{job_id}:cancel
Project and dataset import and export endpoints#
The project import/export and dataset import/export are now handled as jobs.
All import/export trigger endpoints will now return a job ID.
The status of running import and export processes can now be obtained through the job status endpoint.
SDK Updates#
Reduced the dependency size of Geti SDK.
- Benchmarking feature.
Combined with the newly implemented active model switching feature on Geti SDK, the user is now able to benchmark the models’ performance on their machine.
- Multithreaded image upload and download.
Significantly improves the speed of the upload and download process for media binaries.
- A new end-to-end notebook.
Demonstrating features from model creation to deployment, available in notebooks/use_cases.
- Improve the job monitoring feature.
Job progression is now displayed via progress bars.
Python version pinned to 3.11.
Please note: dropping Geti 1.8 version support. Only Geti 2.0 forward is supported.
SDK & REST API Known Issues#
There are breaking REST changes: users should update the code according to the new API specification in the release notes.
The Intel® Geti™ 2.0.0 SDK is not backward compatible with version 1.8.0: users should export the model from the Geti 2.0.0 version to continue using it with the 2.0.0 SDK version.
Intel GPU Known Issues#
MaskRCNN-ResNet50 model may return a 0% score when using small dataset for training detection oriented and instance segmentation tasks.
Web UI Known Issues#
In certain scenarios, the annotations tools may not load properly after an upgrade. If this happens, please clear your browser cache and reload the web page.
Training Known Issues#
Initial training with EfficientNet-B0 and EfficientNet-V2-S on small datasets of low-resolution images, cropped from original images for the detection → classification chain task may lead to some classes not being detected. This issue can be resolved by retraining the models or by supplementing the dataset with more annotations.