Introduction#
Welcome to Intel® Geti™ documentation! Our documentation is broadly divided into the following blocks on the sidebar:
Get Started - Discover what the Intel® Geti™ platform is, eplore its capabilities, and learn how to train your very first model using the Intel® Geti™ platform.
Understanding the UI - Discover the core functionality of the Intel® Geti™ platform and get to know your way around the user interface.
REST API - Learn how to interact with the Intel® Geti™ platform programmatically, bypassing the user interface.
Additional Resources - Understand the fundamental concepts of artificial intelligence, and learn how to optimize the use of the Intel® Geti™ platform with Intel® Hardware, among other things.
On-prem Installation - Dive into the step-by-step process of installing and configuring the Intel® Geti™ platform on your local infrastructure.
What is the Intel® Geti™ platform#
The Intel® Geti™ platform enables enterprise teams to rapidly build computer vision AI models. Through an intuitive graphical interface, users add image or video data, make annotations, train, retrain, export, and optimize AI models for deployment. Equipped with state-of-the-art technology such as active learning, task chaining, and smart annotations, the Intel® Geti™ platform reduces labor-intensive tasks, enables collaborative model development, and speeds up model creation.
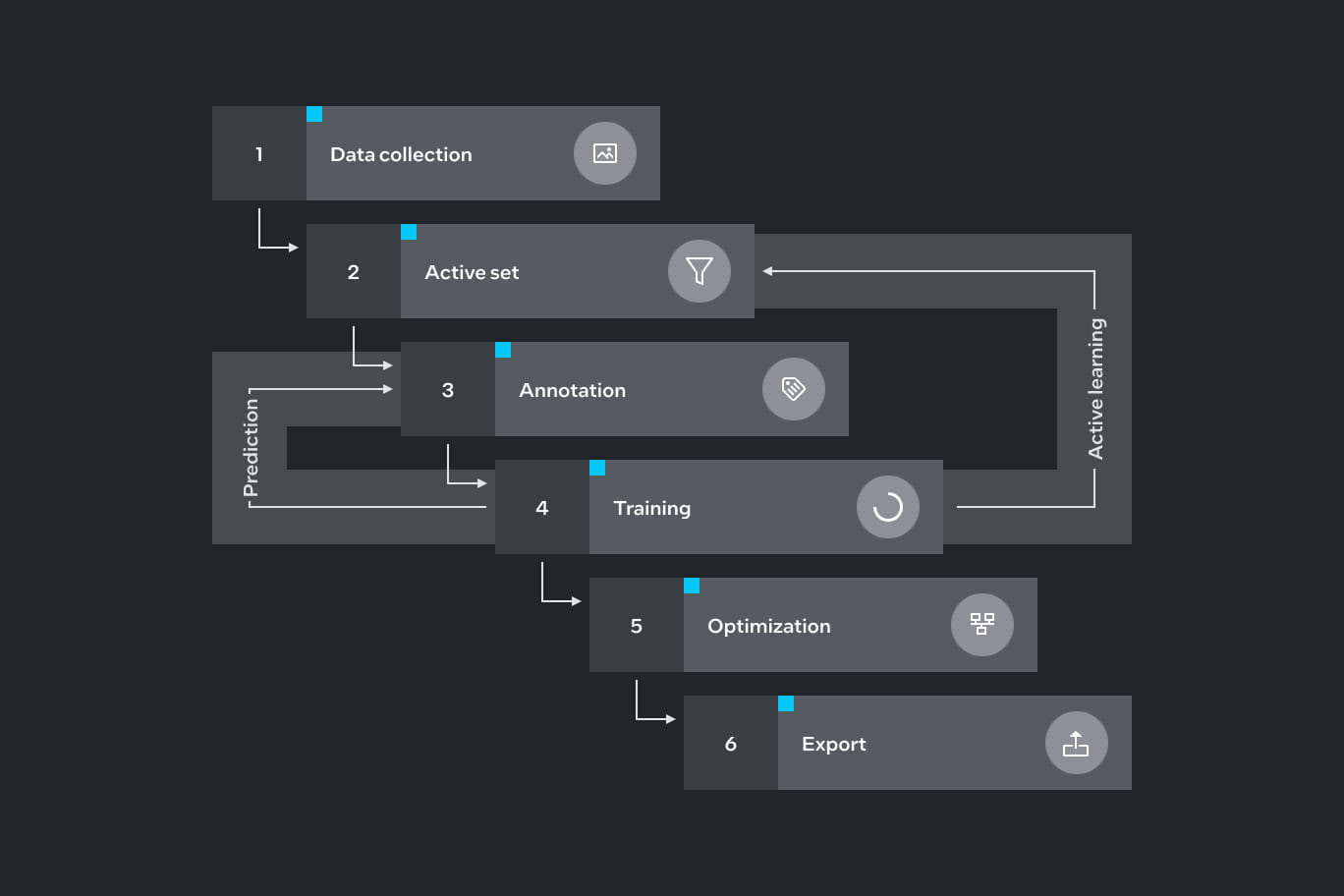
Data Collection - Initially, you need to build your dataset, which will be used to train your model on this dataset. The Intel® Geti™ platform provides a convenient mechanism to annotate your media items during upload for classification and anomaly classification projects. Once uploaded, the Intel® Geti™ platform stores all your datasets (images and videos).
Active Set - This feature automatically selects media items for the most optimal training sessions. The order in which media will appear may seem random and unintuitive but that is not the case. Learn more about this feature in our AI fundamentals.
Annotation - This is the stage where you start teaching a machine how to think. The platform offers a set of tools to facilitate the annotation work. The annotation tools available in the UI vary depending on the type of project you select. Since this is where you will spend most of your time, we made sure to streamline and give you leeway with the way you select labels.
Training - After annotating a predefined number of media items, the Intel® Geti™ platform automatically initiates training on the annotated media (you can also disable that automatic trigger). Trainings occur in sessions after annotating a set of media items. Once the first round of training is complete, the Intel® Geti™ platform will automatically start making predictions on new media items. You can run the training at any time, however, we recommend adhering to the established workflow by the Intel® Geti™ platform.
Optimization - The platform uses the OpenVINO toolkit to optimize models and improve their performance with a write-once, deploy-anywhere approach on Intel hardware. You can also retrain each model version with new parameters at any moment.
Export - You can export your model and integrate it into your application or share it with others.
Human-in-the-loop approach#
The Intel® Geti™ platform relies on human knowledge to annotate the dataset and verify the model’s predictions while training the dataset. Thanks to this human-in-the-loop approach, the model learns faster and becomes more precise. Meanwhile, the platform abstracts away all the technical aspects of data science and software development.
Without the platform for creating models, teams would have to ask a data scientist to train the model. The data scientist would then run the statistical computations on the annotated data and evaluate the model’s prediction accuracy. If the model failed to pass the acceptable threshold, the teams would have to annotate more data, the data scientists would have to tinker with the parameters, or more aspects would have to be covered to detect the issue. Regardless, the process is iterative and continues until the model reaches a satisfactory score.